Introduction
In natural language processing, an excellent evaluation framework is crucial to the development of target tasks or fields. The Word Sense Disambiguation (WSD) task has benefited from some excellent evaluation frameworks and has developed steadily. However, as models effectively identify high-frequency word senses, the current evaluation framework that does not distinguish between high- and low-frequency word senses (that is, head and long-tail word senses) is no longer applicable. In addition, the emergence of Large Language Models (LLMs) requires some effective evaluation frameworks to protect their development. Based on the evaluation framework of WSD proposed by Raganato et al.1, called the original evaluation framework, this website constructs an evaluation framework that distinguishes high- and low-frequency word senses. The evaluation framework can be used to evaluate the ability of WSD systems to identify long-tail word senses,as well as the ability of LLMs to understand and leverage long-tail word senses.
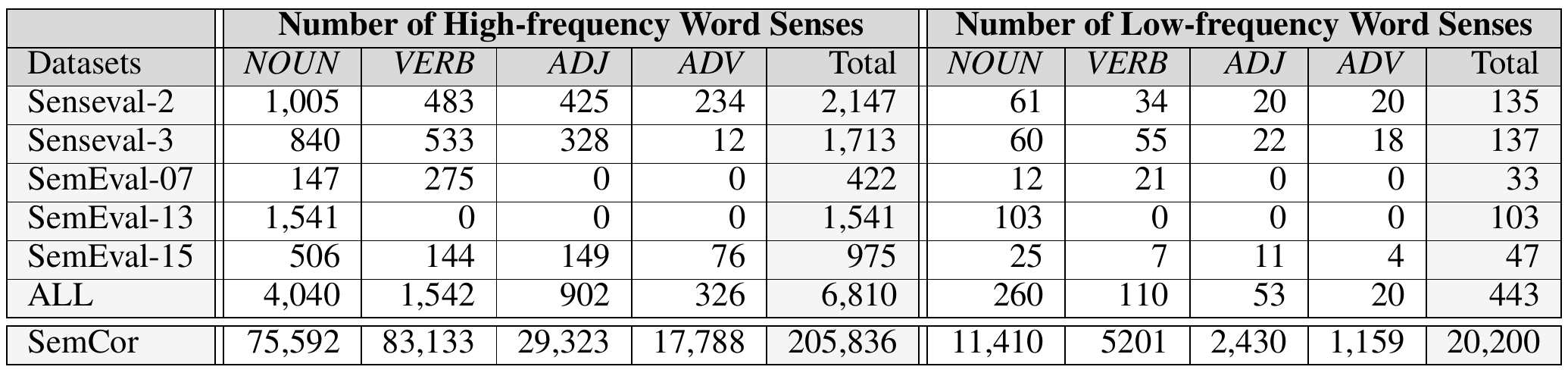
The evaluation framework is based on the original evaluation framework1, and uses ChatGPT-4 and Manual Verification to distinguish high- and low-frequency word senses on the original datasets to finally obtain EF4WSD&LLM. EF4WSD&LLM includes 7 datasets, namely Senseval-2, Senseval-3, SemEval-07, SemEval-13, SemEval-15, ALL and SemCor, of which SemCor is often used as a training set, SemEval-07 is used as a development set, and Senseval-2, Senseval-3, SemEval-13, SemEval-15 and ALL are used as test sets. ALL is a dataset obtained by concatenating Senseval-2, Senseval-3, SemEval-07, SemEval-13 and SemEval-15. The statistical information of high- and low-frequency word senses in each dataset are shown in the table below.
Usage: The usage of this evaluation framework is the same as that of the original evaluation framework1. We just added attributes to distinguish high- and low-frequency word senses in the corresponding tags in the XML text of the datasets. The attribute hf="Yes" in the tag instance represents a high-frequency word sense, whereas the attribute hf="No" represents a low-frequency word sense (that is, long-tail word sense), as shown in the figure below.

Download
The datasets involved in the evaluation framework can be downloaded from the link below. The evaluation metric of this evaluation framework still uses F1-score (%). For other information not covered, please refer to the original evaluation framework1, and its link is http://lcl.uniroma1.it/wsdeval/.
- Senseval-2: download
- Senseval-3: download
- SemEval-07: download
- SemEval-13: download
- SemEval-15: download
- ALL: download
- SemCor: download
Evaluation
In order to verify and analyze the evaluation framework, two parts of analysis experiments were constructed under the word sense disambiguation task and under the large language models. For the model construction method that validates the ability of large language models to understand and leverage long-tail word senses, please refer to the corresponding published paper of the evaluation framework (the paper is currently in the submission status, and the link will be released in time after acceptance). The experimental results are shown below.
1. Evaluation in WSD:
BEM2 (ACL 2020): Moving Down the Long Tail of Word Sense Disambiguation with Gloss-Informed Biencoders. LINK: arxiv.org GitHub

EWISER3 (ACL 2020): Through the 80% Glass Ceiling: Raising the State of the Art in Word Sense Disambiguation by Incorporating Knowledge Graph Information. LINK: ACL Anthology
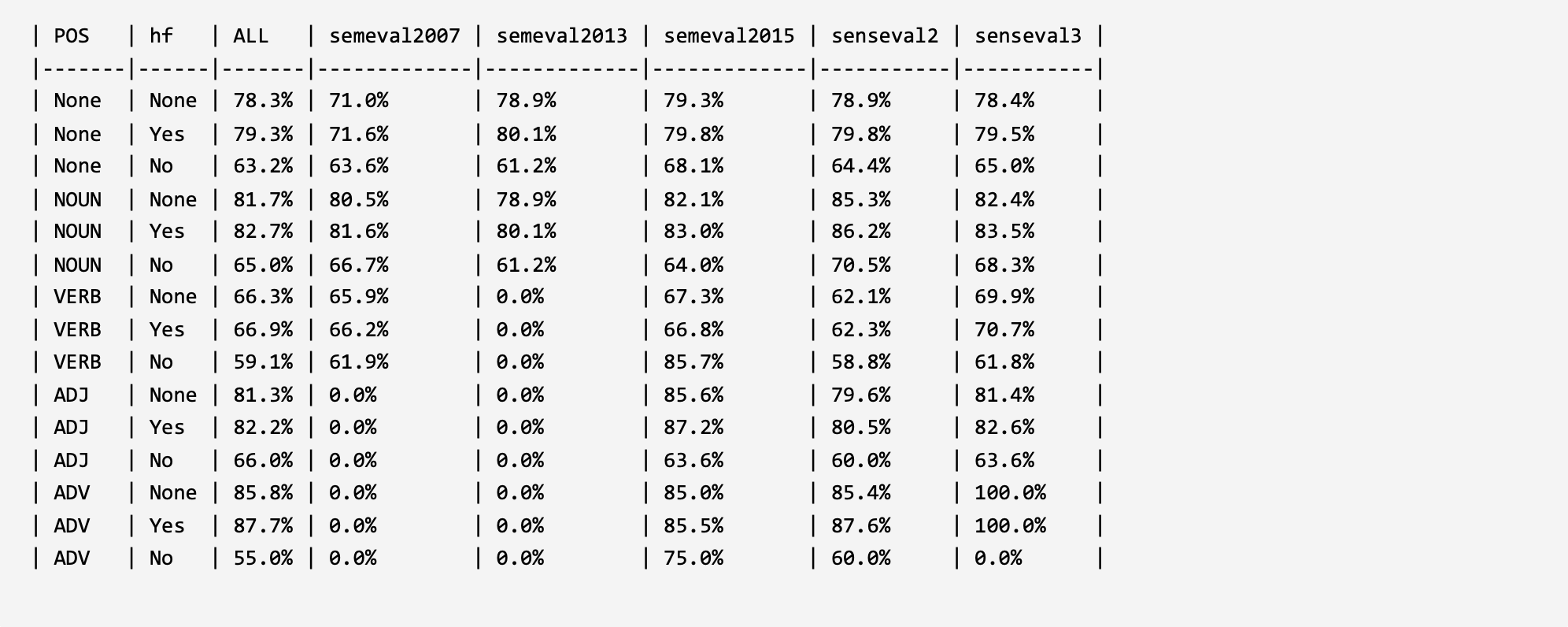
ESR4 (EMNLP 2021): Improved Word Sense Disambiguation with Enhanced Sense Representations. LINK: ACL Anthology
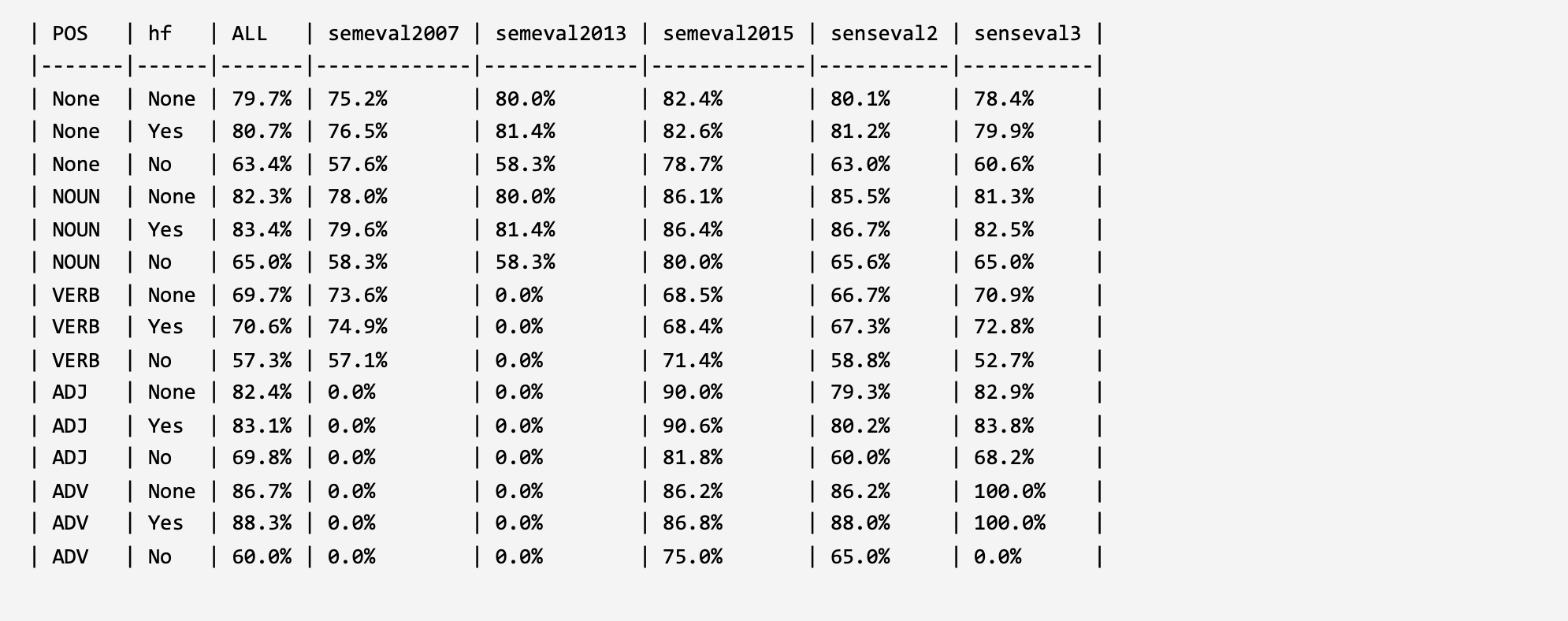
KWSD5 (KBS 2020): Word Sense Disambiguation: A comprehensive knowledge exploitation framework. LINK: GitHub ScienceDirect
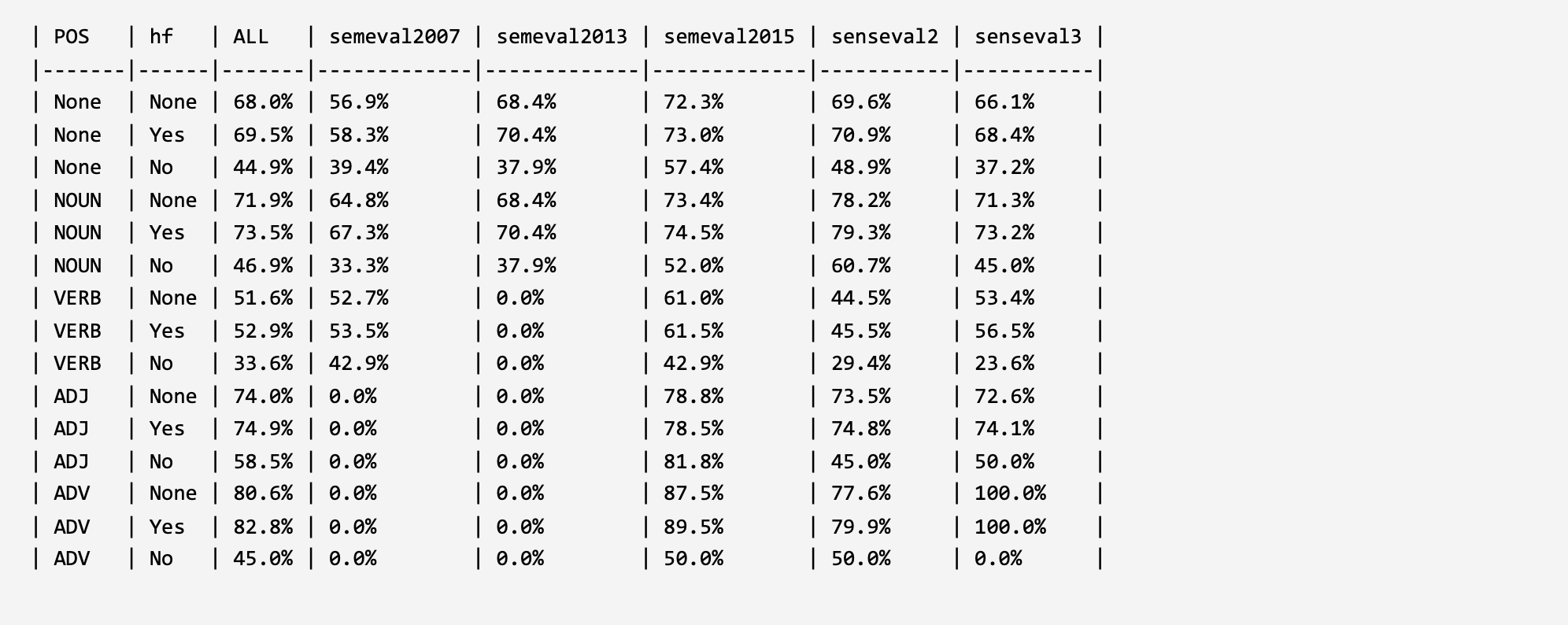
BERT-WSD6 (EMNLP 2020): Adapting BERT for Word Sense Disambiguation with Gloss Selection Objective and Example Sentences. LINK: GitHub arxiv.org

GlossBERT7 (EMNLP 2019): GlossBERT: BERT for Word Sense Disambiguation with Gloss Knowledge. LINK: GitHub arxiv.org
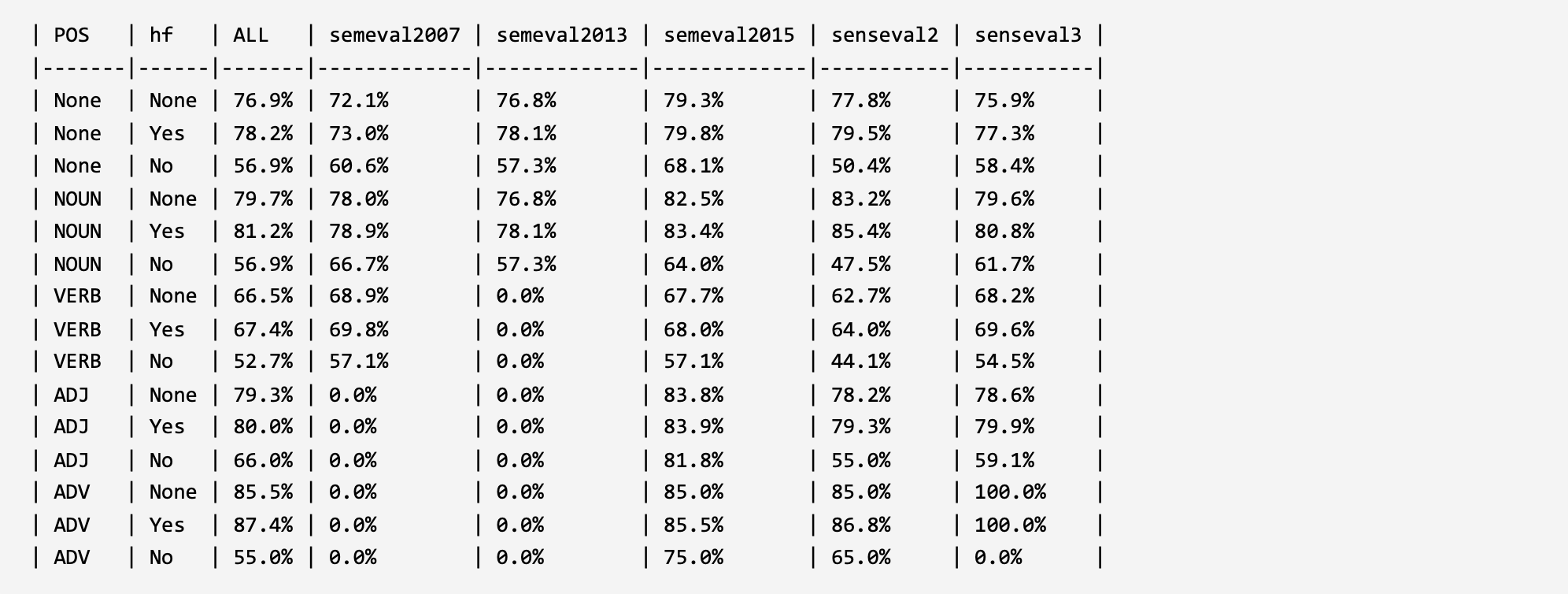
ESC8 (ACL 2021): ESC: Redesigning WSD with Extractive Sense Comprehension. LINK: GitHub ACL Anthology
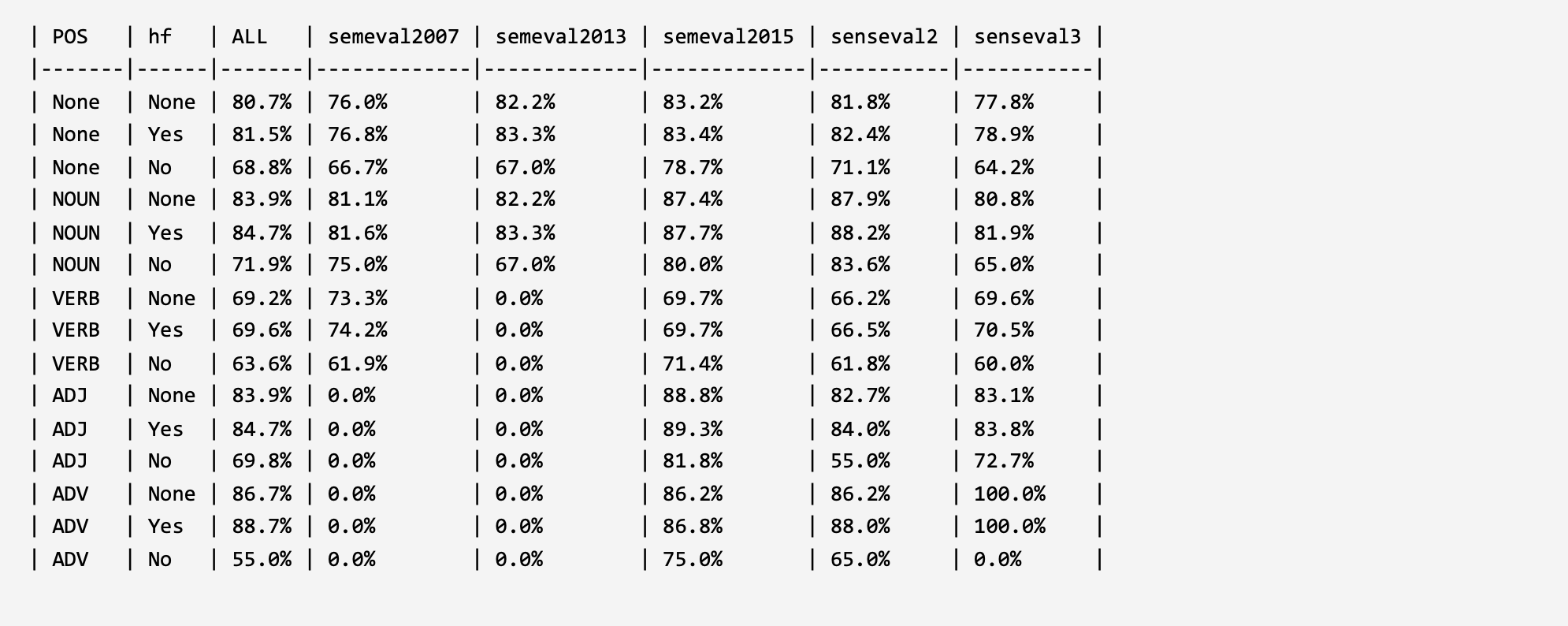
SemEq-Base9 (EMNLP 2021): Connect-the-Dots: Bridging Semantics between Words and Definitions via Aligning Word Sense Inventories. LINK: GitHub arxiv.org
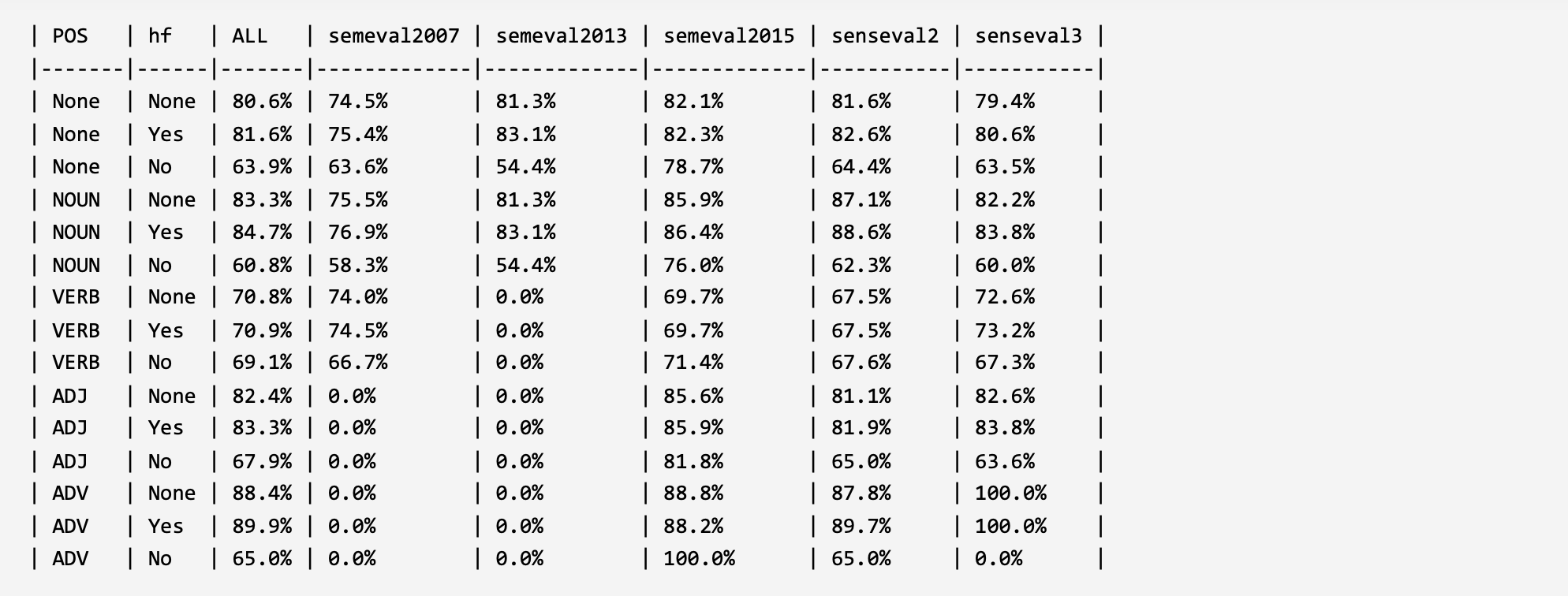
ARES10 (EMNLP 2020): With More Contexts Comes Better Performance: Contextualized Sense Embeddings for All-Round Word Sense Disambiguation. LINK: uniroma1.it
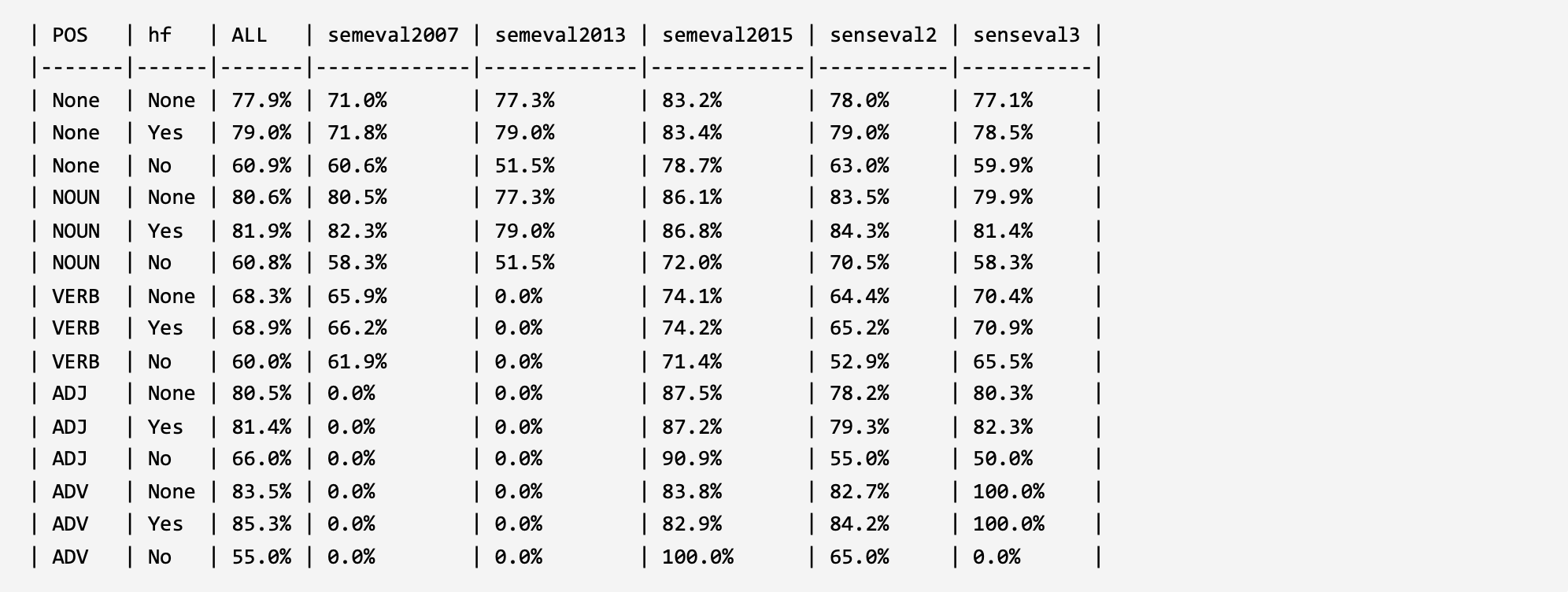
LMMS11 (ACL 2019): Language Modelling Makes Sense: Propagating Representations through WordNet for Full-Coverage Word Sense Disambiguation. LINK: GitHub ACL Anthology
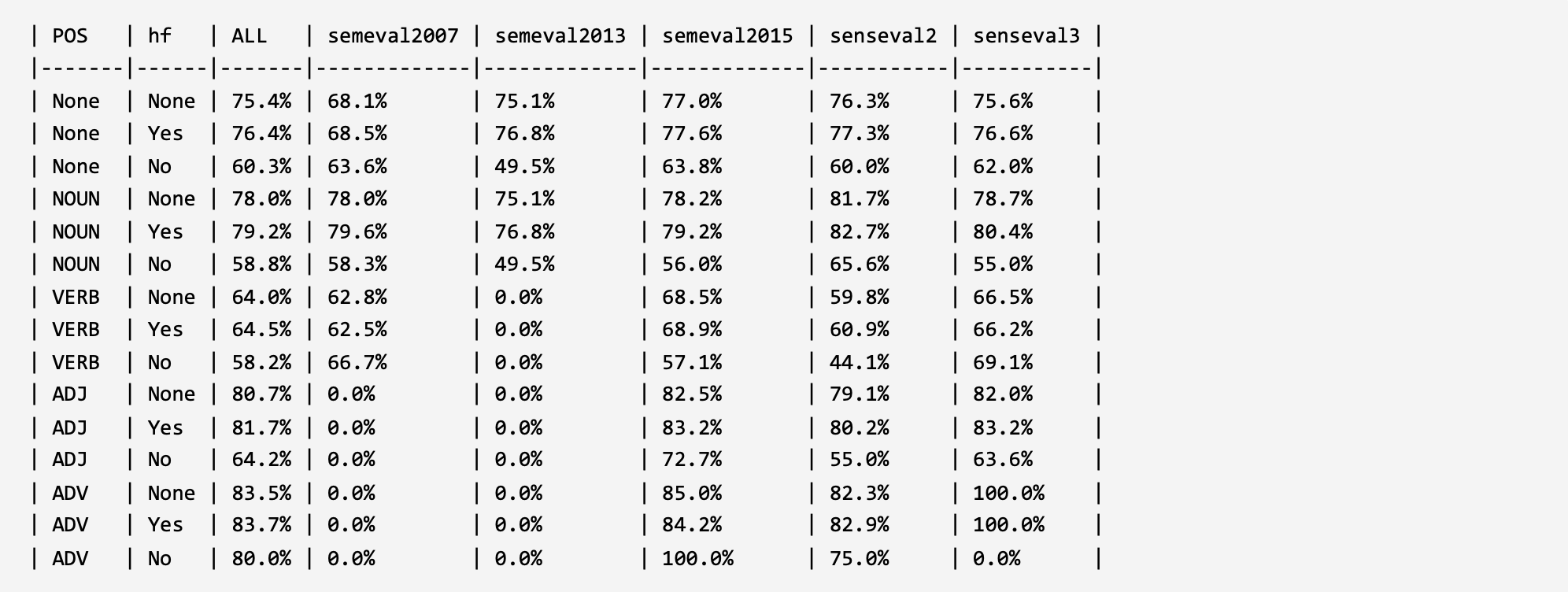
Syntagrank12 (ACL 2020): Personalized PageRank with Syntagmatic Information for Multilingual Word Sense Disambiguation. LINK: ACL Anthology
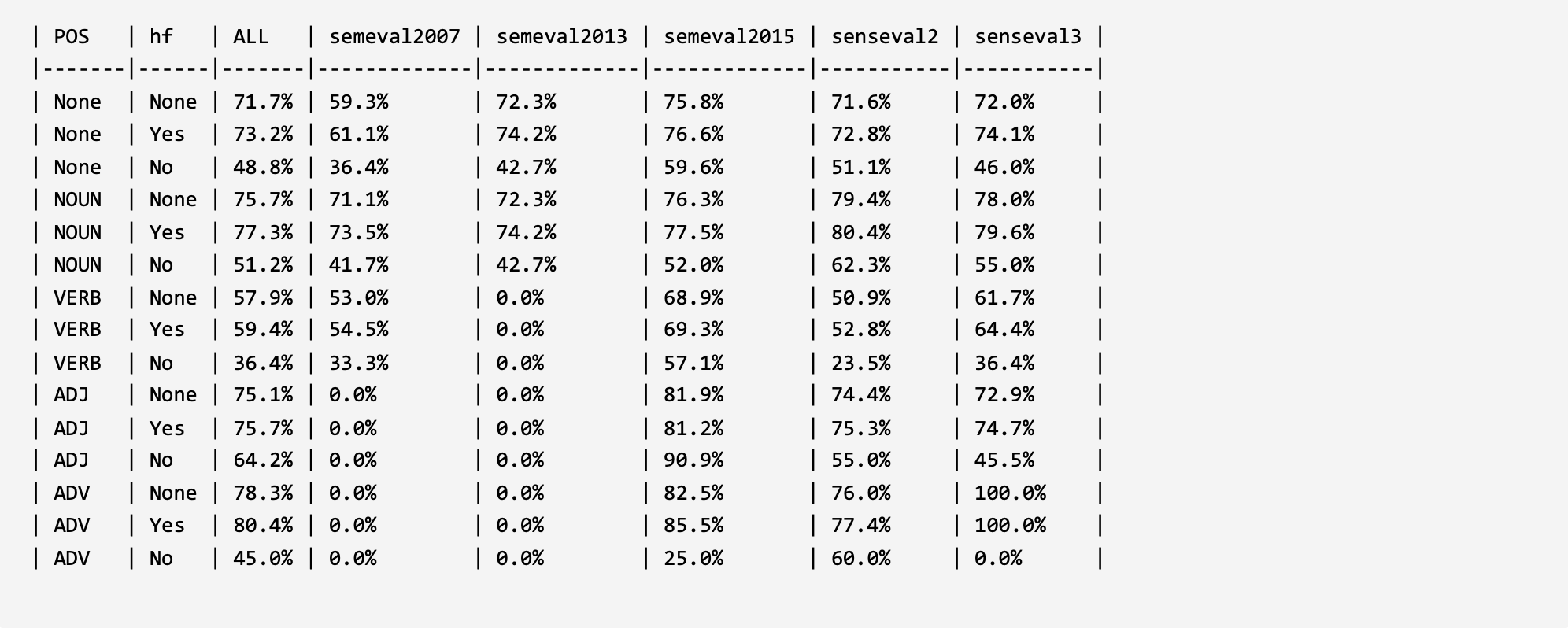
Generationary13 (ACL 2020): Generationary or “How We Went beyond Word Sense Inventories and Learned to Gloss”. LINK: ACL Anthology
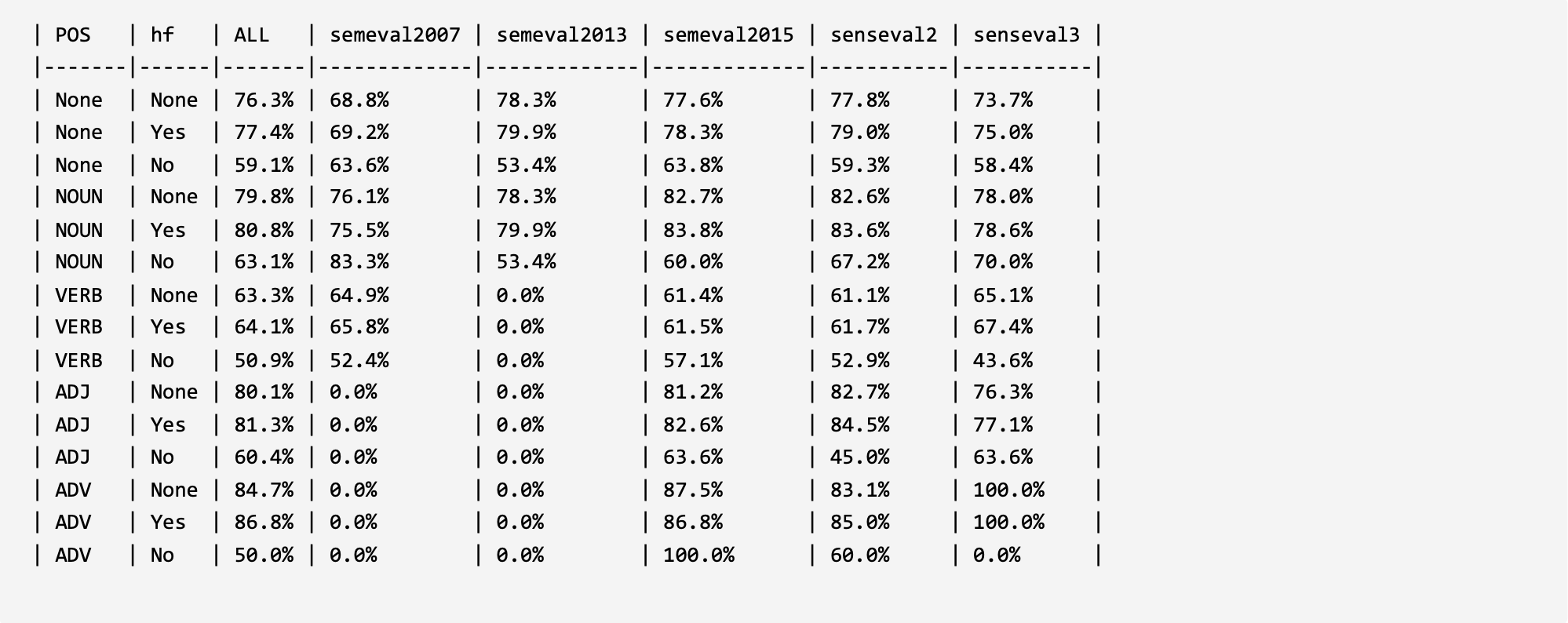
SS-WSD14 (EACL 2023): Semantic Specialization for Knowledge-based Word Sense Disambiguation. LINK: GitHub arxiv.org
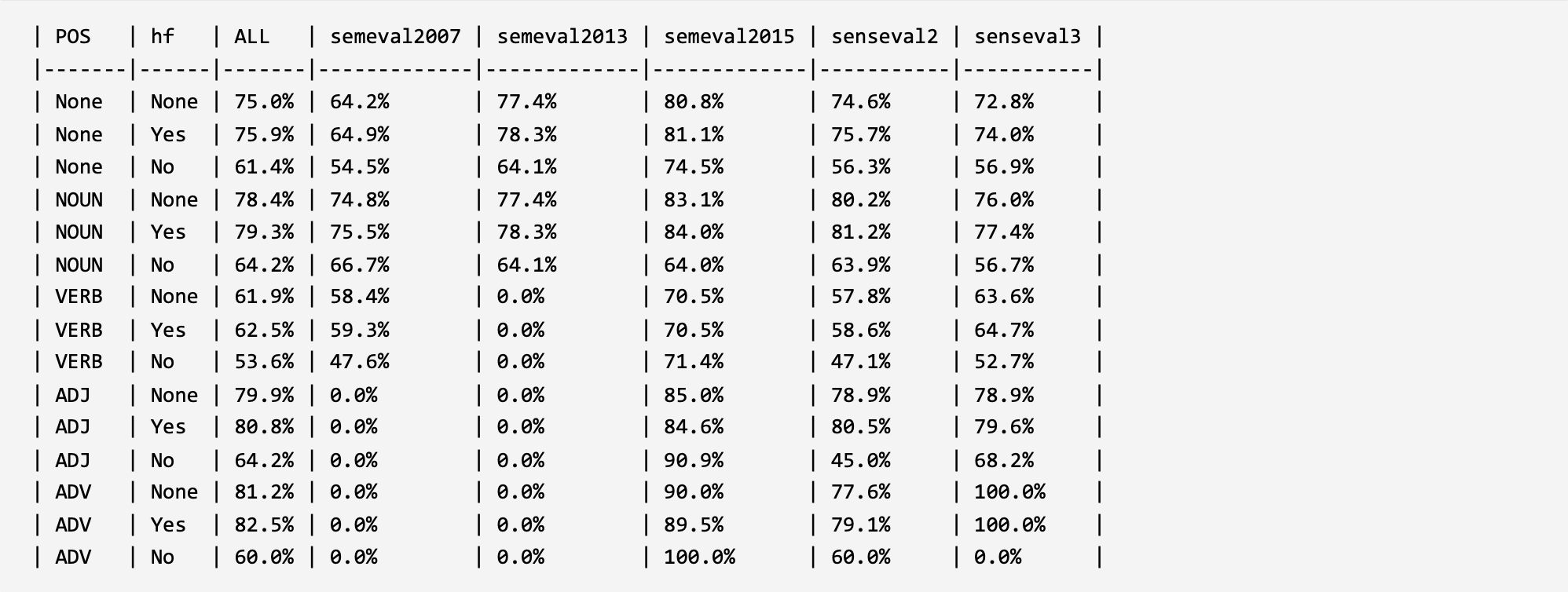
2. Evaluation in LLMs:
See the original paper!
References
- Alessandro Raganato, José Camacho-Collados, Roberto Navigli: Word Sense Disambiguation: A Unified Evaluation Framework and Empirical Comparison. EACL (1) 2017: 99-110
- Terra Blevins, Luke Zettlemoyer: Moving Down the Long Tail of Word Sense Disambiguation with Gloss-Informed Biencoders. CoRR abs/2005.02590 (2020)
- Michele Bevilacqua, Roberto Navigli: Breaking Through the 80% Glass Ceiling: Raising the State of the Art in Word Sense Disambiguation by Incorporating Knowledge Graph Information. ACL 2020: 2854-2864
- Yang Song, Xin Cai Ong, Hwee Tou Ng, Qian Lin: Improved Word Sense Disambiguation with Enhanced Sense Representations. EMNLP (Findings) 2021: 4311-4320
- Yinglin Wang, Ming Wang, Hamido Fujita: Word Sense Disambiguation: A comprehensive knowledge exploitation framework. Knowl. Based Syst. 190: 105030 (2020)
- Boon Peng Yap, Andrew Koh, Eng Siong Chng: Adapting BERT for Word Sense Disambiguation with Gloss Selection Objective and Example Sentences. EMNLP (Findings) 2020: 41-46
- Luyao Huang, Chi Sun, Xipeng Qiu, Xuanjing Huang: GlossBERT: BERT for Word Sense Disambiguation with Gloss Knowledge. EMNLP/IJCNLP (1) 2019: 3507-3512
- Edoardo Barba, Tommaso Pasini, Roberto Navigli: ESC: Redesigning WSD with Extractive Sense Comprehension. NAACL-HLT 2021: 4661-4672
- Wenlin Yao, Xiaoman Pan, Lifeng Jin, Jianshu Chen, Dian Yu, Dong Yu: Connect-the-Dots: Bridging Semantics between Words and Definitions via Aligning Word Sense Inventories. EMNLP (1) 2021: 7741-7751
- Bianca Scarlini, Tommaso Pasini, Roberto Navigli: With More Contexts Comes Better Performance: Contextualized Sense Embeddings for All-Round Word Sense Disambiguation. EMNLP (1) 2020: 3528-3539
- Daniel Loureiro, Alípio Jorge: Language Modelling Makes Sense: Propagating Representations through WordNet for Full-Coverage Word Sense Disambiguation. ACL (1) 2019: 5682-5691
- Federico Scozzafava, Marco Maru, Fabrizio Brignone, Giovanni Torrisi, Roberto Navigli: Personalized PageRank with Syntagmatic Information for Multilingual Word Sense Disambiguation. ACL (demo) 2020: 37-46
- Michele Bevilacqua, Marco Maru, Roberto Navigli: Generationary or "How We Went beyond Word Sense Inventories and Learned to Gloss". EMNLP (1) 2020: 7207-7221
- Mizuki S, Okazaki N: Semantic Specialization for Knowledge-based Word Sense Disambiguation. arXiv preprint arXiv:2304.11340, 2023.
Contact
See the original paper!